Xiao-Li Meng is the IMS President for 2018–19. He writes:
No vibrant society would want as its president someone who feels entitled to the honor, or treats it as an honorary title. I am therefore honored by your trust, and shall do my best to earn the honor. No society is entitled to vibrancy either, regardless of its past laurels, without ongoing and on-target efforts by its membership and leadership. For those inclined to consider this assertion merely a new president’s scare tactic, my Chicago colleague Stephen Stigler’s historical account, “Does the American Statistical Association Have a Future?” (Amstat News, August 2004, pp 2–3), would be a timely read.
“But why should I care about IMS’s vibrancy?” some of you may ask. “Duh!” perhaps is the most expected answer from any IMS president, but let’s elaborate on that “Duh.” Don’t worry, I am not here to preach about why you shouldn’t ask what IMS can do for you (you should), but rather ask what you can do for IMS (you can). Nor am I here artfully to back out of any “read-my-lips” campaign promises. I didn’t make, or rather need, any. IMS decided a long while ago, wisely, that a sure way to eliminate empty campaign promises was to eliminate the campaign. “Conditioning is the soul of statistics,” as my Harvard colleague Joe Blitzstein emphasizes in all his teaching. The vote of confidence I received was conditioned on N=1, where N is the population size of candidates determined by the nomination committee (thanks a bunch!). My previous “N=2” experiences (at ASA and ISBA) reminded me that this conditional confidence should give me little confidence that the majority of IMS members actually endorse the three priorities in my candidate statement, or even know what they are. Indeed, when I asked about what to write for the President Column, I got a clear message that I should not make the obnoxious assumption that the majority of members actually know who I am. This gives me a perfect excuse to invoke n=1, interweaving a few personal stories with the thinking behind the three priorities. As a (reputable) statistician, I am well aware of the danger of relying on n=1 (or any n). My hope is that these stories can help personalize messages that otherwise may be perceived to be mostly rhetorical.
I was trained, during 1978–1982, as a pure mathematician at Fudan University in Shanghai. Like thousands of youths then in China, I was attracted to mathematics not because I understood any of its applications, but because of an inspiring article on Jingrun Chen, a mathematician who, back in the early 1970s, had made the most significant contribution towards solving the Goldbach conjecture. By comparison, the statistical profession has relied almost exclusively on the applicability and impact of statistics to attract students, researchers and the public’s attention. This has been working increasingly well as we enter more deeply into the digital age. For instance, the Statistical Sciences department at the University of Toronto now attracts more than 3500 undergraduate students from all walks of (college) life to its statistical programs, apparently because of the greater job prospects; see the report here. Even if only a small percentage of them end up being a card-carrying statistician or probabilist, the large denominator greatly drives up the numerator.
There is still more we can and should do, however. For instance, the pure-math community constantly attracts some of the world’s most powerful minds, as well as public fascination, by emphasizing (wisely) not the job prospects of mathematicians, but the sheer intellectual challenges created by the community, from Fermat’s last theorem to the twin prime conjecture. As I argued in XL-Files, job prospects can fluctuate greatly even for seemingly infallible fields (e.g., CS). Yet to solve world’s most difficult problems, as they accumulate, requires an increasing supply of creative minds and deep thinkers. A nano-sample of such problems might include: formulating and guiding data utility and data privacy trade-off, building a general theory for cost-effective and information-preserving data preprocessing, establishing a rigorous evaluative framework for individualized treatments, analytical modeling of digital blockchain networks, coherent statistical learning with many and diverse low-resolution input, and deep understanding of deep learning. It would be a missed opportunity if we do not also emphasize their intellectual demandingness, including being harder to formulate than mathematical conjectures, when conveying their importance and impact. The joy of intellectual pursuit is catnip for brilliant minds, and IMS, being the world’s leading scholarly society for mathematical statistics and probability, is a natural home for such minds. Therefore, we should also compete for them to the fullest extent.
Young minds (of whatever biological age) are not only more curious, they are also more likely to make good use of the joy implicit in “aha” moments as fuel for the drive to overcome increasingly higher-
level obstacles. In my own case, although I did well enough in middle school to forgo high school, I ran into a major learning block upon encountering the concept of open sets at college. I just couldn’t comprehend the notion “open” without connecting it to a geometric object. It took a whole week for me to realize that it is fruitful to let the meaning of a property outgrow its original root. I still recall how joyful I was when I finally “got it!” My ability to engage in abstract thinking took off after that “aha” moment. I started to seek difficult abstract concepts instead of avoiding them, ultimately leading me to study abstract algebra for my senior thesis. IMS should cultivate interest from college students from around the world, and from all data science-oriented fields, who live for such moments of intellectual exhilaration. Relative to the pool of graduate students, undergraduates represent an even larger supply of extraordinary minds, with increasingly diverse backgrounds. Indeed, once when I was writing a recommendation letter for a PhD student, I had to replace “the best student” by “the best PhD student,” upon realizing that the most original thinker I ever worked with was an immigrant undergraduate student, whose senior thesis is far deeper than my PhD thesis (and most of my publications).
When I started to take courses at Harvard in 1986, I encountered my second learning block. I was well advised, by a classmate from Fudan who had come to the US a year earlier, to take some hard courses and some easy ones, in order to achieve a “grade-learning balance.” Unfortunately, he neglected to tell me which courses were easy and which ones were hard. Probability Theory was obviously hard, and Regression Analysis surely was on the easier side: how hard could it be to draw a reasonable line across a bunch of points? The reality opened my eyes and my mind. My homework answers on Probability Theory were used by the instructor to replace the TA’s answers, thanks to years of training in getting the right answers in the most elegant and succinct ways (getting right answers would only earn partial credits then). For the regression homework, I knew how to start, but didn’t know when to stop. The residual plots always had the shapes—especially when I stared at them long enough—that my textbook said I should avoid. I took log of Y, and of X, and of both of them, and sometimes log of log Y. Shapes changed, but never disappeared. The book told me to also try the square root transformation. So I did. I also cleverly avoided taking a square root of the square root—there was something called the Box-Cox transformation. More shapes emerged, and some were more amusing than others. But the young course instructor was not amused, when I handed in about 100 pages of computer output. I was called to his office, and I was asked to explain what I had done. I was frustrated. If I had known what I was doing, would I have handed in all 100 pages?? Thankfully, my English was so poor then that soon the instructor had to let me go, saving both of us from going from regression to aggression.
Recently, the same instructor—now a senior professor at a world class university—and I reminisced about those good old days with a few colleagues. He said that he didn’t recall that encounter at all. Instead, he told everyone how once I cracked a mathematical problem for the course on the spot, a problem that he had struggled with for days. I, of course, was flattered, but didn’t have the slightest memory of it. The conversation reminded me of how young minds are more likely to be impressed, not depressed or suppressed, by challenges. It is also a telling example of the effectiveness of having people with different training and experiences work together to solve challenging problems. Back then the ratio of my understanding and skills in probability to that in statistics was essentially infinite, and hence I was more useful for mathematical and theoretical problems. By now, the ratio is essentially zero—I didn’t intentionally decrease the numerator, but I have tried hard to grow the denominator. I now have a far better understanding of the residual plots (I hope!), and much deeper statistical insights with which to conduct principled corner-cuttings and formulate foundational research problems, such as those in “A Trio of Inference Problems that Could Win You a Nobel Prize in Statistics (If You Help Fund It)” (http://www.stat.harvard.edu/Faculty_Content/meng/COPSS_50.pdf). But to tackle these problems, I am in far more need of probabilistic and other analytical skills than the young instructor was in need of my mathematical skills more than three decades ago.
Generally speaking, foundational problems in data science require penetrating statistical and computational thinking, complex probabilistic modeling, and intricate mathematical derivations. As my predecessor, Professor Alison Etheridge, rightly and repeatedly stressed in her presidential address during the 2018 IMS annual meeting, there is an increasingly urgent need for statisticians and probabilists to work together as a team, within and beyond IMS, to tackle the most challenging problems in data science. She also stressed the importance of being as inclusive and supportive as possible, for example to female probabilists and statisticians. We need to work together, continuously and creatively, to ensure that IMS excels as a scholarly society for mathematical statistics and probability, establishing and sustaining a socially welcoming and intellectually supportive hub and professional network for young talents in statistics, probability, and more broadly data science. Our key aim is to facilitate collaboration and career development, especially for those who are in most need.
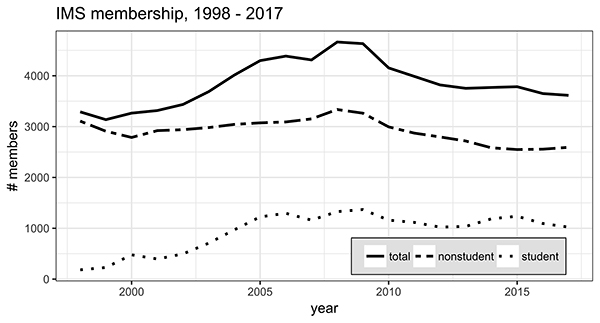
With these priorities in mind, I was very encouraged when NSF (the US National Science Foundation) contacted me during the JSM at Vancouver, inviting IMS to play more a leading role in conducting foundational research for data science, and in helping NSF to shape its priorities and strategies for various data science initiatives, such as the HDR (Harnessing the Data Revolution) investment (https://www.nsf.gov/news/news_summ.jsp?cntn_id=244678&org=CI). As a small but immediate step, I have requested the leadership of IMS Data Science Group to accelerate their efforts to organize a cross-disciplinary conference on Foundations of Data Science, and to increase their emphasis on attracting and accommodating young talents from probability, statistics, computer science, and beyond. I am also forming an IMS Task Force, consisting of probabilists and statisticians, with the charge to recommend strategies and activities aimed at building younger, broader, and deeper pipelines, in terms of demographical and intellectual spectrums. IMS is not immune to the phenomenon of declining membership; see, for example, the trends in the figure below, especially the non-student membership. Yet our vibrant future lies not only in increasing our numbers, but in enriching the scholarly community of probabilists, statisticians, and, more broadly, data scientists. We aim to strengthen our existing foundations, as well as to break the ground within which new ones can be built.
To summarize, foundations cannot be simulated; they necessitate designing, digging, and excavating, and hence, powerful minds and muscles. If IMS is to play a more leading role in building the foundations of data science, probabilists and statisticians need to work more closely and more frequently. This aim should compel us to cultivate collaboration and communication early on in the careers of young talents, and to be as inclusive and supportive as possible in our pipeline-building effort. IMS will also serve data science, and itself, well by attracting many more extraordinary talents from all walks of life, who derive joy and develop perseverance from intellectual challenges themselves. The more broadly and deeply we can attract and engage such talents, the more effectively IMS can lead in building the foundations of data science. Our vitality depends upon exercising our capacities to carry out the tasks right in front of us, while taking a long view of the intellectual challenges that are as yet far beyond us.
Thanks for indulging my long “Duh,” going from vibrancy to vitality. Increasingly, I find myself hoping that I am aging like Château Musar (I cannot afford Château Lafite, at least not those from Château Lafite). But there is no escape from the reality that in youth (which is both an inward and outward quality) lies vitality. I surmise that few of you would have the patience to hear yet another anecdote from my youth to illustrate this point. But in case you feel your time has been wasted reading my anecdotes, I’m happy to refund your time by reading your stories (president@ims.org), especially if they can inspire us to build, collectively, a more vibrant and vital IMS.
Until the next time (with stories from the older me), please stay young and vibrant!
Comments on “President Xiao-Li Meng’s Message: IMS–Younger, Broader, and Deeper”