Richard Davis delivered his IMS Presidential Address at the World Congress in Probability and Statistics, at the Fields Institute in Toronto on July 11, 2016. The video of this talk, which includes slides and three embedded videos can be accessed from http://www.fields.utoronto.ca/video-archive or http://www.stat.columbia.edu/~rdavis/PresidentAddress2016.ogv (the address starts at the 14:45 mark).
—
Toronto, a world-class city with experience in hosting large statistics meetings, is a near-perfect venue for this Congress. Toronto has been on the regular circuit for JSMs since 1983 and is also a beacon for high level research in both probability and statistics.
So I would like to begin this address by acknowledging some people who have strong connections to both Toronto and IMS. I will start with David Brillinger (pictured below with Murray Rosenblatt). He is a former president of IMS, and also a professional hockey player wannabe. His enthusiasm for statistics, and life, is infectious and makes him a great ambassador for statistics. He will be delivering the Tukey lecture tomorrow and who better to talk about Tukey than David.

David Brillinger (right), with Murray Rosenblatt. Murray will be turning 90 later this year and there is a conference in his honor later this fall, co-organized by Dimitris Politis and Ruth Williams
The second person I would like to acknowledge is Nancy Reid. She is also a former president of IMS and has won virtually every trophy in statistics that one can win. Now she has gone beyond that: she became an Officer of the Order of Canada last year, and just a few months ago she was named a Foreign Associate of the National Academy of Sciences. This is quite a year to have both of those honors bestowed on her.

Nancy Reid, pictured with ‘father of statistics in Canada’ Don Fraser
I had a difficult time coming up with a title for this talk. After all, it’s not every day that one gives a President’s Address. For inspiration, I looked at the addresses from the previous three IMS presidents [you can read these at https://imstat.org/category/presidential-address/]. Hans Künsch spoke about Ars Conjectandi in 2013, the 300th anniversary of the publication of Bernoulli’s masterpiece. An easy choice, I thought. Interestingly, he included comments on neuroscience and, in particular, predictive reverse engineering. Towards the end of this address, I’ll mention an example from neuroscience that illustrates exactly that sort of issue. Two years ago, Bin Yu inspired us with her talk on “Let Us Own Data Science” [also at https://www.youtube.com/watch?v=92OjsYQJC1U], about how we should get our act together relative to data science. And then last year, Erwin Bolthausen lamented the potential separation between probability and statistics. He worried that the two disciplines may be drifting apart.
I finally settled on the title—“Are we meeting the challenge?”—which may sound a little lame. The answer to this question is an unequivocal yes! (You don’t ask a question like this without delivering a positive answer.) Of course, the question is not well defined until one specifies the challenge. You can make the challenge anything you want. So that was essentially the challenge: to determine what the challenge should be. The challenge here is to adapt and be relevant to the changing advances in technology and science. And where did I come up with something like this? I was inspired by Miron Straf’s 2002 ASA President’s Address, “Statistics: The Next Generation”1. The 2002 JSM happened to be in New York, about 10 months after 9/11. The mood was still subdued in New York. And Miron gave what I viewed as a somber and depressing address, and not because of 9/11. Miron is an extremely articulate and engaging person. He was the Associate Director of Behavioral and Social Sciences of the National Academy of Sciences and for number of years wrote a humor column on the last page of Chance. I don’t usually attend President’s Addresses but I happened to attend this one since I had just become an ASA fellow2. Miron delivered what I viewed as a pessimistic long view of the future of statistics. To reinforce his point, he quoted from Leo Breiman’s 2001 article, “Statistical Modeling: The Two Cultures”3 that appeared in Statistical Science as a discussion paper with a distinguished group of discussants consisting of Cox, Efron, Hoadley and Parzen. Although a relatively new article at the time of Miron’s address, Breiman’s paper has become rather influential with over 1400 citations. Breiman also appeared a bit depressed about the future direction of statistics. In a recent unpublished manuscript, “50 years of Statistical Science”4, David Donoho provides an excellent discussion of Breiman’s two cultures and delves into the comments by the discussants.
Returning to Miron’s address, he was certainly prescient in his prediction of the impact of technology on virtually all aspects of our lives. In describing how our discipline will have to change he says, “…change for us is not an option. Technology and its interaction with social, political, and economic factors will force change upon us. Suppose we as a profession do not change our ways, while the world around us changes. Imagine then, our world in 2020.” I cherry-picked some of the items that he forecasted for statistics in the year 2020. (Remember, it was 2002 when he gave this talk.)
• Decentralized work environment—impact of generation III of internet
• Academics selling distance learning courses
• Demand for statistics degrees diminishes—statistics departments dissolve
• Printed journals (and even refereed ones) will give way to online journals
• Big meetings will be replaced by Web-based alternatives (“with air travel unsafe and unnecessary”)
So as a method of keeping score on the predictions, I will award a ✓ or ✘ for correct/wrong forecasts. The first item has certainly come to fruition. We shop from home, work from home, even teach from home. This item definitely gets a ✓. The next item also gets a ✓. What university administrator does not want to market online courses—it’s believed to be another way to generate income for declining university budgets. The third item, that the demand for statistics degrees and some stat departments may dissolve, is way off the mark. I will award this item with two ✘’s. I will show some data later demonstrating that the demand for statistics is healthier than ever. (If it’s not clear by now, this is going to be an upbeat message about the statistics profession!) In item four, Miron is spot on and receives a ✓. Many printed journals, even refereed ones, have given way to online journals. As for the last item, big meetings will be replaced by web-based alternatives, because air travel is unsafe (again, recall this was in 2002, and the mindset was that people would severely scale back air travel), he got this one wrong. The impressive attendance at this World Congress is evidence that we still attend conferences in person.
Let’s return for a minute to Breiman’s two-culture paper. The two cultures refer to data modeling and algorithmic modeling (or as it is better known today as predictive modeling). In data modeling, the setup is traditional. We entertain a statistical or stochastic model for the data, fit the model to the data, and then do the traditional model assessment and inference. In algorithmic modeling, it is more like a “black box” approach, where you try to fit some type of model to the training data and assessment of the model’s performance is governed primarily by its ability to predict well. What I found interesting is at the end of Breiman’s rejoinder to the discussants, he appears exasperated and writes, “Many of the best statisticians I have talked to over the past years have serious concerns about the viability of statistics as a field. . . .The danger is that if we define the boundaries of our field in terms of familiar tools and familiar problems, we will fail to grasp the new opportunities” (emphasis added). This perspective is echoed to a large extent by Straf. My outlook on the state of the profession and its future is more upbeat.
• By its very nature, the statistics discipline is necessarily nimble and adaptable to new scientific disciplines, to new types of data forms, to new scientific questions, etc.
• Why would this view change in the face of the technological onslaught with “big data”? It may take more time and more manpower, but it will happen and is happening!
• The warning issued by Straf and Breiman seemed mostly pessimistic in view of the history of the subject? Maybe this pessimism was essentially a “call to arms?”
• It is a false choice between theory and applications or “empirical corroboration” vs “theoretical mathematical validation”5
• Is the “theory” vs “applied” mindset based on a zero-sum principle? Can’t we embrace both—need a “larger tent” for statistics.
My view is we should argue for a bigger tent that embraces both “theory” and “applications.” Or as Efron wrote—as only he can with such clarity—in his comment to Breiman’s paper: “There are enough physicists to handle the physics case load, but there are fewer statisticians and more statistics problems, and we need all the help we can get.”
So how are we doing? Let’s use some subjective metrics. In the media, the view about statistics has changed. In the late 1990s, early 2000s, when Miron delivered his address, there were rumblings that computer science was going to eat our lunch and we would be out of a job. It wasn’t the most popular of fields and statistics was struggling to cope with new forms of data. But look at how the perception of statistics has changed in the media. Nate Silver (fivethirtyeight.com) is a statistician who made a name for himself with his nearly spot on predictions of the 2012 US elections featuring Romney versus Obama in the presidential race. To many democrats, he provided much needed sanity in the face of conservatives who were convinced that Romney was going to win easily. In the regular and online media, “Triumph of the Nerds: Nate Silver Wins in 50 States” was a common post-election refrain. Of course, everyone knows the famous and often repeated quote by Hal Varian, the chief economist for Google. The extended quote, which appeared in 20096, is “I keep saying the sexy job in the next ten years will be statisticians. People think I’m joking but who would’ve guessed that computer engineers would’ve have been the sexy job of the 1990s?” Everyone was gravitating towards computer science in the late 1990s, early 2000s. Notice the phrase “the next ten years”: the expiration date is nearly upon us. We only have a few years to enjoy being sexy. I’m not sure what happens after that…

http://www.bls.gov/ooh/math/statisticians.htm
The Bureau of Labor Statistics listed the 2015 median pay as $80,000 for just a master’s degree in statistics [see table above]. That’s not a bad situation. In the next ten years, 2014–24, they forecast a 34% increase in the number of jobs in statistics. That translates to 10,100 new jobs. As many of you know Columbia has a large master’s program so that we have dibs on half of those new positions for our students!
How about in academia? Let’s think about the way we train statisticians of the future.
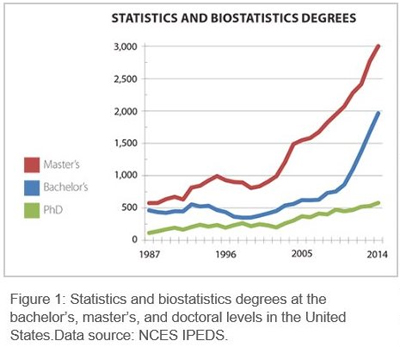
The graph [above] shows the trends for the number of awarded degrees [from top to bottom, the lines represent Master’s, Bachelor’s and PhDs] in statistics and biostatistics from 1987 through 2014 (data from Steve Pierson, Amstat News Oct 2015 and NCES). The top curve, corresponding to masters degrees, has shown impressive growth from around 2000. This is perhaps due primarily to an influx of Asian students populating our US master’s programs. I took a quick look at some statistics departments, mostly in the US, that have MA stat programs and have displayed a summary of the sizes of the respective programs in Table 1 [below].
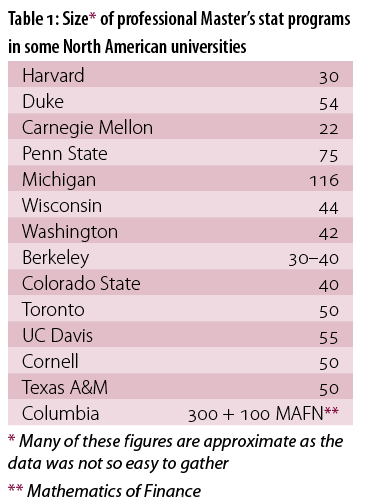
For many of these universities, the professional Master’s degrees represent an extra revenue source for the university. The curriculum for these professional programs has changed markedly from the traditional training in statistics. It is no longer the usual, probability, math statistics, linear regression style-curriculum, but sprinkles in required or elective courses in a suite of subjects that one could call machine learning, data science, and/or statistical computing. So this aspect of how we train the next generation of statisticians has changed.
In Miron’s address, he mentioned how statistics departments need to change. I think it is worth pausing to examine the sort of changes that have already occurred. First, the makeup of faculty in terms of their background has changed. It used to be that maybe only half a dozen statistics departments had someone who didn’t have a degree in mathematics or statistics. But now, many of the top departments who are expanding and who are infected with the data science bug, are hiring researchers with a broader background in computer science, electrical engineering, OR, neuroscience, etc. And this goes back to what Bin was saying in her address. I don’t think we need to hire a more disciplinary diverse group of faculty at the expense of excluding theory and the core, that’s the zero-sum mindset. We need to expand and get larger.
Let me finish with an example from neuroscience. This example is based on the work of John Cunningham, one of my colleagues in the statistics department at Columbia, and Mark Churchland, a neuroscientist at Columbia. This particular example has to do with how the motor cortex in the brain controls voluntary movement. There are perhaps hundreds of neurons of many millions that control this movement. [A video is displayed of a paraplegic male who is attempting to draw a circle on a computer screen using a bionic mouse that is receiving “instructions” from multiple neurons.] This video is maybe fifteen years old and the results are not so great, but not horrible either. In another example, consider a research subject trying to touch his/her finger on top of a red square located on a computer screen. The red square keeps moving and the research subject tries to keep up. Signals in the form of spike trains are received from neurons that control the movement of the arm. For each dot displayed on the screen, a large number of time series (100, say) are recorded together with the location of the research subject’s finger. One might consider the following state–space model for this situation.
Let Xt=(post, velt)T be the position/velocity of the research subject’s fingertip at time t. In addition, we also have the time series Yt generated from the 100 neurons. A simple model takes the following form.
Training Data:
fingertip position/velocity: $X_t$=$\begin{bmatrix}pos_t\\vel_t\end{bmatrix} ∈ ℝ^4$
state of the 100 neurons: $Y_t ∈ ℝ^100$
Model:
$X_t = AX_{t-1} + ϵ_t$
$Y_t = CX_t + w_t$
The coefficient matrices A4×4, C100×4, and noise characteristics are estimated from a training data set (Xt,Yt), t=1, …, T. Now for newly collected neuron data, Y1, Y2, …, the goal is to predict Xt, t≥1, based on knowledge of the instructions produced from the neuron firings Y1, Y2, …, Yt. In other words, one needs to compute E(Xt | Y1,…,Yt). Assuming the noise terms are iid and Gaussian, this is a fairly straightforward calculation using the Kalman filter. In the video clip, one can see how well a research subject can control a bionic mouse, which is receiving instructions from the controller connected to his brain. The controller receives the Yt’s, calculates the conditional expectations of the Xt’s, and uses this information to control the mouse. There are a number of limitations in this modeling framework such as:
• the data are not Gaussian; on fine timescales, the data Yt are multivariate counts.
• Yt may be under-dispersed, which can be harder to model.
• Observation model is not linear and a more general distribution for Yt | Xt
should be specified. In this case, the computation of E(Xt | Y1,…,Yt) is more complex.
John and his collaborators have worked on various aspects of these extensions. With a more sophisticated approach, one can see in the second video the improved performance of the controller.
This neuroscience example exemplifies how statisticians are meeting the challenge. First, this illustrates the collaboration between a statistician and a scientist. Second, John, the statistician in this activity, has broad training in statistics, computer science and electrical engineering. The tools brought to bear on this problem come from all three disciplines, including statistical theory and computation. Third, the research has a real societal impact. It not only has the potential of making people’s lives better, but it is enhancing understanding of how the brain works.
Like many others, I believe we have entered a golden era of statistics. It may be difficult to pinpoint the start of this era, but let’s hope we are not in a bubble that will burst anytime soon. Challenges still remain. As Bin mentioned in her president’s address, we need to be players in new initiatives that are coming down the pike, from data science and bigger data to precision medicine. So, while I think we are meeting the challenge and are doing reasonably well, there is still a lot to do. We will continue to see an evolution of the fundamentals of statistics and probability in the coming years, which is as it should be.
I would like to finish on a personal note. The first paper I ever published, which I wrote while in graduate school appeared in the Annals of Probability in 1979. Back then it was not so typical that students would publish while in graduate school. You would first complete your thesis and then publish the chapters later.

Richard’s first paper, in the Annals of Probability in 1979
As you can see [first page is displayed on projector] the paper was first received in 1977. Some things, like a backlog, never change in the Annals of Probability! Even the start of the first sentence—“Let Xn, n=1, 2, …, be a stationary sequence of random variables…”—doesn’t change. I presented this paper at the 1978 JSM in San Diego. I met a number of people there and one or two of them became long-time collaborators. I became a member of IMS that same year in 1978, and when I joined I didn’t think to ask the question what does IMS do for me? It just seemed like the right thing to do. Perhaps like many people starting out, I never knew if I would write another paper. I think back then students had to pay dues for IMS (it is now free for students!) and I have continued to pay my annual dues out of my own pocket. Maybe that’s laziness, because I could pay the fees from research funds—I just need to provide the invoice to the department accountant. But maybe there’s another reason why I continue to pay myself: to me, being a member of IMS is not just professional, it’s also personal.
Thank you.
Footnotes
1 Straf, Miron L. “Statistics.” Journal of the American Statistical Association (2011). See: http://www.straf.net/pdfs/jsm-speech-jasa.pdf
2 Like IMS, ASA couples the awards banquet with the President’s Address in order to get a larger audience. As an aside, this is one reason I have been pushing to have more fellows in IMS: to increase attendance at our awards banquet.
3 The use of the colon in titles was popular in the early 2000’s!
4 Donoho presented this paper at the Tukey Centennial birthday celebration at Princeton in 2012
5 Terms used in Straf’s president’s address.
6 The McKinsey Quarterly, 2009
Comments on “Presidential Address: Are We Meeting the Challenge?”