
Each year the outgoing IMS President delivers an address at the IMS Annual Meeting, which, this year, was the Australian Statistical Conference in Sydney (July 9-14, 2014), a joint meeting of the Statistical Society of Australia Inc. (SSAI) and IMS. Bin Yu, Chancellor’s Professor of Statistics and EECS, University of California at Berkeley, gave her Presidential Address, on which the following article is based:
Let us own data science
It is my honor and pleasure to deliver this IMS Presidential Address at the joint meeting of the Statistical Society of Australia Inc. (SSAI) and IMS.
Data science is all the rage in the media. Most people would agree that it has three pillars: computer science, statistics/mathematics and domain knowledge (some believe data science is the intersection of the three as shown in the figure (below) while others think it is the union.)
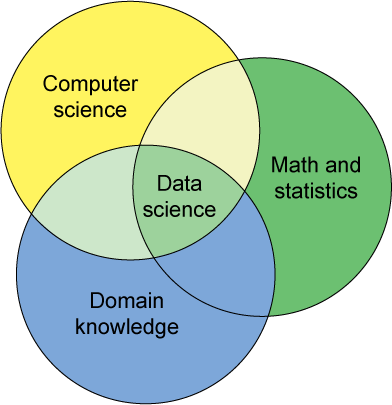 [Image credit]
[Image credit]
Today, we — SSAI and IMS — have gathered in the beautiful city of Sydney. Let’s turn the clock back 67 years to 1947, when the Statistical Society of New South Wales (SSNSW) was formed here in Sydney. A group of statisticians met at the University of Sydney in the spring of 1947 to start a society of statistics in order to further “the study and application of statistical methods in all branches of knowledge and human activity.” I was very pleased to learn that the first President of SSNSW was a woman (in 1947!): Helen Newton Turner, 1908–95, who first worked at CSIRO as a statistician and later decided to become a geneticist.

Helen Newton Turner, the first president, in 1947, of the Statistical Society of New South Wales, which was to become the first chapter of SSAI. [Image credit]
Her obituary noted: “Not many scientists in Australia have contributed as much and as directly to the growth and well-being of a major Australian industry [wool] as she did. Not that she would have agreed with this description; she was a very modest woman and would have said, ‘It wasn’t me, it was my team’.” Clearly, Turner and her collaborators made a huge impact in domain science (animal breeding) and the wool industry, and worked as a team, all hallmarks of data science today.
The obituary goes on to describe Turner’s three main contributions as “…an experimental scientist, introducing objective measurement methods into breeding […] as a communicator and publicist of the new methods [and] as an educator of postgraduate students and Department of Agriculture staff.” Turner was a superb educator and communicator to the public, again desirable traits of a data scientist.
If we turn the clock back a further 17 years, to 1930s Ann Arbor, we would meet Professor Harry C. Carver (1890–1977) in the Mathematics Department of University of Michigan.

Harry C. Carver.
Carver started and was the first editor of The Annals of Mathematical Statistics (later split into AOS and AOP), which marked the beginning of IMS. He was a mathematical statistician (no surprise) and an aerial navigation expert (big surprise!). The US Air Force bestowed on him the highest honor in peacetime: Decoration for Exceptional Service, for his contributions to air navigation.
Carver took leave from the University of Michigan and enrolled himself in an Air Force school as an ordinary cadet and trained and studied with all the young cadets for a year. He then returned to Ann Arbor and started teaching a course on air navigation. (Carver was a believer in what he did: on approaching retirement at 70, he devised a “retirement desirability” objective function for US locations—average temperature, total rainfall, number of days of sunshine, etc.—and used weather records to optimize this function to find the best retirement location [Santa Barbara, California] and there he moved. )
Carver also recognized keenly the importance of computing machines in air navigation. In the preface to his 1943 book, An Introduction to Air Navigation, he wrote, “…logarithms must be considered now as a tool of the past. Present-day commercial institutions almost without exception use computing machines rather than logarithms in the conduct of their business in the interest of efficiency in both time and labor: moreover progressive schools now have installations of these machines that enable their students to work more problems in less time than formerly.”
Perhaps, through a modern lens, Carver could be viewed as an early “machine learner” and he was carrying out “on-line learning” or “streaming data analysis” since in air navigation, planning, recording, and controlling the movement of an airplane have to be done very fast or in real time. Interested in the speed of computing for air navigation, he got the first Hollerith Tabulating Machine at University of Michigan. Carver’s “on-line” analysis seems mostly point estimation via optimization (possibly with some uncertainty considerations), however, hence in the spirit of modern-day machine learning.

A Hollerith Tabulating Machine. Photo: Wikipedia/Marcin Wichary
{kind=link}
Who, we may ask, is Hollerith? Wikipedia tells us Herman Hollerith (1860–1929) was also a statistician, and an inventor. He founded the Tabulating Machine Company that was later merged with three other companies to become IBM. Wikipedia reads: “Hollerith is widely regarded as the father of modern machine data processing. With his invention of the punched card evaluating machine the beginning of the era of automatic data processing systems was marked. His draft of this concept dominated the computing landscape for nearly a century.”
The motivation for his invention of the Hollerith Tabulating Machine arose from the 1890 US Census. It was predicted that it would take 13 years to process the census data, but the census is every 10 years in the US, by law. Faster data processing tools had to be found. Hollerith came up with the idea of punched cards to store census records: a hole or not indicates a male or a female, for example. Note that this binary storage format is similar to the binary storage format in a digital computer. The next challenge for Hollerith was to have these punched cards read automatically to add up counts. He solved this by taking advantage of Edison’s invention of electricity with an electric counting machine that registers a count when the electricity is allowed to flow with a hole.
Putting the traits of Turner and Carver together gives a good portrait of a data scientist:
• Statistics (S)
• Domain/science knowledge (D)
• Computing (C)
• Collaboration/teamwork (C)
• Communication to outsiders (C)
That is, data science = SDCCC = $SDC^3$.
Just like Turner and Carver, many of the later prominent statisticians were also “data scientists”. William Cochran (1909–80) was instrumental in establishing four statistics or biostatistics departments across US universities, at Iowa State, NC State, Johns Hopkins, and Harvard. He was also a recipient of ASA’s prestigious Samuel S. Wilks Medal. In the introduction to his book Sampling Techniques, he wrote “Our knowledge, our attitudes, and our actions are based to a very large extent upon samples. This is equally true in everyday life and in scientific research … But when the material is far from uniform, as is often the case, the method by which the sample is obtained is critical, and the study of techniques that ensure a trustworthy sample becomes important.”
Non-uniform sampling is an important issue to address in big data problems, since with the increased size of data comes the increased heterogeneity or non-uniformity.
John W. Tukey (1915–2000) was best-known for his invention of FFT with Cooley. He created Exploratory Data Analysis (EDA) and made it accepted in the statistics community. He received a US Medal of Science and might have defined “data science” accurately in his 1962 article, “The Future of Data Analysis”:
“It will still be true that there will be aspects of data analysis well called technology, but there will also be the hallmarks of stimulating science: intellectual adventure, demanding calls upon insight, and a need to find out ‘how things really are’ by investigation and the confrontation of insights with experience.”
According to Wikipedia, Tukey’s principles of statistical practice have been summarized by A.D. Gordon. I paraphrase these principles below and believe they serve well as principles of data science:
• Usefulness and limitation of theory
• Importance of robustness
• Importance of massive empirical experience of a method for guiding its use
• Importance of data’s influence on methods chosen
• Rejection of the role of “police”
• Resistance to once-for-all solutions and over-unification of statistics
• Iterative nature of data analysis
• Importance of computing
• Training of statisticians
Clearly, statisticians have been doing a big part of the job of a data scientist today and no existing other disciplines do more than statistics. We need to fortify our position in data science by focusing on training skills of critical thinking (that enables statistics and domain knowledge seeking), computing (that implies parallel computation with memory and communication dominating scalability), and leadership, interpersonal and public communication (that enable collaboration and communication with outside). For the twitter generation, I have a shorter message:
Think or sink; Compute or concede; Lead or lose.
Since we do the job of a data scientist, let’s us call ourselves data scientists! You might ask, what’s the big deal about a name? Well, words do mean things.
Let us take a look at the game of branding. As they evolved, the fields of Statistics and Computer Science have taken very different approaches regarding branding. Statistics uses the same term: “statistics” means different things to different people at different times. Its original meaning was derived from population census in Europe. Now “Statistics” covers a vast range of activities so is not very informative to an outsider. Most people to this day understand it in its original meaning—counting or census—though many statisticians today are part of research on cancer, genomics, neuroscience, and astronomy. By contrast, the data-related sub-field of Computer Science has adopted new names for new developments over time: AI, Data Mining, Machine Learning, Deep Learning…
Imagine an 18-year-old, J, choosing between statistics and data science in college. J’s brain is excited by the new and bored with the old, as clearly shown in the data used in my collaborative work with the Gallant Lab (cf. Nishimoto et al (2011), Current Biology). In this data, clips of movies were shown to a human subject and his/her fMRI brain signals were recorded. When the clips are displayed next to the corresponding brain signals, one can see that the brain is “excited” (high level of activity) at the beginning of a clip, and then most of the time quickly “cools down” (low level of activity).
J probably took an AP statistic class in high school; or if not, J looks up “statistics” on Wikipedia, and finds:
“Statistics is the study of the collection, organization, analysis, interpretation and presentation of data. It deals with all aspects of data, including the planning of data collection in terms of the design of surveys and experiments. When analyzing data, it is possible to use one of two statistics methodologies: descriptive statistics or inferential statistics.”
J finds this description not very exciting, to say the least. So J Googles “statistics” and sees this:
The top picks by Google are all related to the original meaning of statistics about census. “How about ‘statistician’?” J wonders, and finds its definition in Wikipedia as follows:
“A statistician is someone who works with theoretical or applied statistics. The profession exists in both the private and public sectors. It is common to combine statistical knowledge with expertise in other subjects.”
This description is a bit circular and doesn’t speak to J, but J reads on…
“…Typical work includes collaborating with scientists, providing mathematical modeling, simulations, designing randomized experiments and randomized sampling plans, analyzing experimental or survey results, and forecasting future events (such as sales of a product).”
More jargon to J. In the June/July 2014 “Terence’s Stuff” Terry Speed sketches the image of a statistician from the point of view of an outsider:
We (statisticians) “don’t deal with risk, with uncertainty… we’re too absolute, we do p-values, confidence intervals, definite things like that.” We “raise arcane concerns about mathematical methods.” Said a scientist, “I had no interest in very experienced statisticians” … “I wasn’t even thinking about what model I was going to use. I wanted actionable insight, and that was all I cared about.”
These impressions of statisticians would not help J to turn in our direction, if J were to talk to adults about statistics.
Now J turns his attention to “Data Science”. J thinks to himself, “It’s about data and science, and it sounds exciting!” — just as an undergraduate student told me recently when I asked him to choose between statistics and data science. Moreover, Wikipedia gives the following definition:
“Data science is the study of the generalizable extraction of knowledge from data, yet the key word is science.”
This definition is a lot more attractive than statistics’ definition. It is concise and to the point. Going down the Google search result list leads us to an IBM website that states:
“Data scientists are inquisitive: exploring, asking questions, doing ‘what if’ analysis, questioning existing assumptions and processes. Armed with data and analytical results, a top-tier data scientist will then communicate informed conclusions and recommendations across an organization’s leadership structure.”
Doesn’t this sound like an applied statistician’s description? I wonder how many statisticians in academic departments relate to this description as their job description and for what percentage.
Recalling the fact that J’s brain is excited by the new and bored by the old, we ask what would J choose, statistics or data science?
A good new name like data science has power. For example, a data science MA program attracts a lot more applicants than a statistics MA program; Moore–Sloan foundations established three data science environment centers; Moore Foundation is giving DDD investigator awards; and universities are looking into data science FTEs.
Many of our visionary statistics colleagues saw data science coming. Professor Jeff Wu claimed “data science” as our own as early as 1998. In Wu’s inaugural lecture of his Carver (yes, that Carver!) Chair Professorship at University of Michigan, he proposed that we change “statistics” to “data science” and “statistician” to “data scientist”. He went on to say that “several good names have been taken up: computer science, information science, material science, cognitive science. ‘Data science’ is likely the remaining good name reserved for us.” My late colleague Professor Leo Breiman (1928–2005) was a probabilist, statistician and machine learner. His inventions included CART (with collaborators), Bagging and Random Forests. In his 2001 seminal paper “Statistical modeling: the two cultures” in Statistical Science, he wrote: “If our goal as field is to use data to solve problems, then we need to move away from exclusive dependence on data models and adopt a diverse set of tools.”
Data Science represents an inevitable (re)-merging of computational and statistical thinking in the big data era. We have to own data science, because domain problems don’t differentiate computation from statistics or vice versa, and data science is the new accepted term to deal with a modern data problem in its entirety. Gains for the statistics community are many, and include attracting talent and resources, and securing jobs for our majors, MAs and PhDs.
How do we own it? The answer is not hard. We just have to follow the footsteps of Turner, Carver, Hollerith, Cochran and Tukey, and work on real problems. Relevant methodology/theory will follow naturally. The real problems of today come from genomics, neuroscience, astronomy, nanoscience, computational social science, personalized medicine/healthcare, finance, government, to name just a few. Hence it is not surprising that a 2011 McKinsey Report “Big data: The next frontier for innovation, competition, and productivity” predicts that “There will be a shortage of talent necessary for organizations to take advantage of big data. By 2018, the United States alone could face a shortage of 140,000 to 190,000 people with deep analytical skills as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.”
As a community, we statisticians have to act. Some suggestions: at an individual level, you could put “data scientist” next to “statistician” on your website and resume if your job is partly data science; aim to get on interesting and/or important data projects; upgrade your computing, interpersonal and leadership skills; scale up algorithms and carry out data science research (e.g. analysis of parallel and/or random algorithms).
As a community, our public image needs much improvement. We could all prepare a two-minute elevator pitch in lay terms, ready to talk to non-statisticians to diversify our “counting” image; we could give public speeches and interviews with media when opportunities arise; we could blog and tweet; we could upload YouTube videos about statistics and our own work; and we could update our websites with accessible descriptions of research. The most urgent is to update the statistics and data science Wikipedia pages, possibly by asking our students in classes to help.
As a community, we need to write vision statements and/or white papers to persuade deans and upper administrations and funding agencies to provide resources (money and positions)—recall that Cochran started four statistics/biostatistics departments!—for us to make major contributions to data science. We need to reform statistical curricula (especially introductory courses); we need to put out MOOCs or online (multi-media) courses that integrate the essence of statistics and computing principles, with interesting modern data problems as examples.
IMS is doing its bit to engage us in data science. An IMS–MSR Data Science Conference is planned for 2015 in Boston, entitled “Foundations of data science: Synergies between statistics and machine learning”. I am pleased to announce the organizing committee consists of three co-chairs: David Dunson, Rafa Irizarry, and Sham Kakade, and four other members, A. Braverman, S. Dumais, A. Munk, and M. Wainwright.
Moreover, we have run an IMS membership drive to attract young people, especially young machine learners, into IMS. And I would like to use this opportunity to tell you that in 2015, IMS Named and Medallion Lecture nominations will be open to the community. Watch out for announcement at http://imstat.org/awards/lectures/nominations.htm
To summarize:
• Let us own data science
• Think or sink;
• Compute or concede;
• Lead or lose.
Thank you for your attention!

4 comments on “IMS Presidential Address: Let us own Data Science”